Precision and Recall in an anomaly detection situation
reference :
ROC 커브는 False Positive Rate(FPR)을 기준으로 True Positive Rate(TPR)의 변화도를 표현한다. 아래 첫번째 분포곡선에서 임계값(beta)이 이동함에 따라 TPR과 FPR이 변화한다는 것을 예상해볼 수 있다.
임계값이 우측으로 이동하면 FPR과 TPR 모두 줄어든다. 반대로 임계값이 좌측으로 이동하면 FPR과 TPR모두 커진다.
즉, 확률상 0이라는 지점은 사실상 없다고 생각하기 때문에(-무한대) 임계값이 완전 좌측으로 이동했을 때 TP와 FP 수 모두 0으로 수렴하고 확률(R)도 0에 다다른다.
확률(R)이 0인 지점(-무한대)에서 임계값 축이 다시 우측으로 출발한다고 가정하면, FPR과 TPR 모두 즉시 줄어들지만 실제 값 음성의 분포가 좌측에 있으므로 FPR이 더 빠르게 감소하게 되고, TPR은 서서히 줄어들게 된다.
이를 그 아래 좌표평면으로 ROC Curve로 표현할 수 있다.
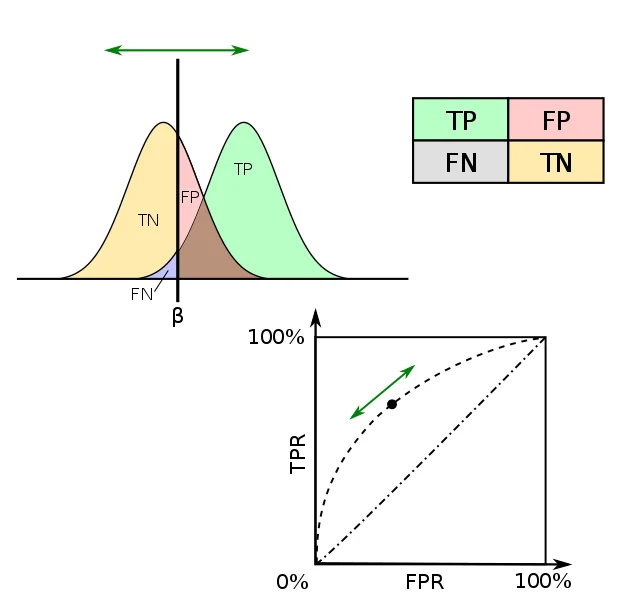
ROC Curve plotted when threshold β is varied. Source: Wikimedia Commons 2015.
만약 실제 값 음성 분포와 실제 값 양성 분포의 중심축(데이터가 충분히 많아서 정규분포에 근사한다고 가정할 때 평균에 해당)이 충분히 서로 멀어서 FP(Positive로 오판)와 FN(Negative로 오판)이 크게 감소한다면, 즉 겹치는 영역이 0에 가깝다면 ROC 커브는 좌상향으로 볼록하게 솟아오른다. 좋은 이진분류 모델은 아래 이미지에서 보라색 ROC 커브를 보여준다.
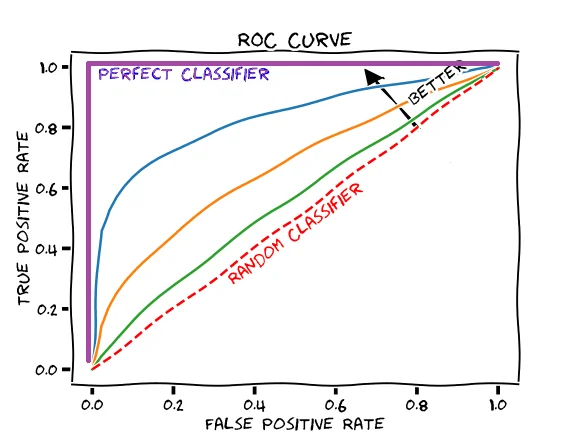
Glass box, Rachel Draelos
code example
1
2
3
4
5
6
7
8
9
import matplotlib.pyplot as plt
from sklearn import datasets, metrics
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
X, y = datasets.make_classification() # 분류 모델을 위한 데이터 자동 생성
X_train, X_test, y_train, y_test = train_test_split(X, y) # 학습, 검증 데이터셋 분리, default : 25%
model = XGBClassifier()
model.fit(X_train, y_train) # training data로 모델 학습
1
print(model.score(X_test, y_test))
0.92
1
metrics.plot_roc_curve(model, X_test, y_test)
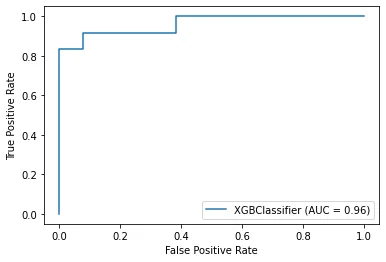
관성을 이기는 데이터